
CoMModO Post-Processing: Automatisierte, KI-basierte Analyse von Finite-Element-Simulationsergebnissen als nächste revolutionäre Innovation von ANDATA
von Niklas Stalanich (Kommentare: 1)
Ausgehend von den Entwicklungen im Themenfeld der Versagensprognose mit CoMModO führt ANDATA gerade eine weitere, neue, radikale Innovation in der erfolgreichen Anwendung von Künstlicher Intelligenz (KI) ein: KI-basierte, automatisierte Struktur-Analyse im Post-Processing von Finite-Element-Simulationen sowie deren Integration in Simulation Data Management Systemen. Der vorliegende Blog beschreibt die grundlegenden Motivationen und Ideen dahinter.
Einleitung und Kontext
Unter dem Markennamen CoMModO (Complex Material Modeling Operations) hat ANDATA bereits 2006 mit dem Einsatz von Künstlichen Neuronalen Netzen in der Finite Element-Simulation (FE-Simulation) zur Versagensprognose begonnen. Ausgehend vom damaligen, preisgekrönten Forschungsprojekts CoMModO wurden dafür vier ineinandergreifende Lösungspakete definiert, welche in Form von Engineering-Dienstleistung mit den dazugehörigen Werkzeugen bei ANDATA verfügbar sind:
- Parameterschätzung für konventionelle, analytische Material-, Element- und Komponenten-Modelle mittels Machine-Learning-Modellen (daten- bzw. beispiel-basierten Modellen)
- Kalibrierung und Validierung von konventionellen, analytischen Material-, Element- und Komponentenmodellen mittels Evolutionsverfahren und stochastischer Simulation
- Machine-Learning-basierte (neuronale) Modelle für Materialien, Elemente und Komponenten innerhalb der FE-Simulation
- Anforderungsmanagement und Test-Design für Material-, Element- und Komponenten-Modelle
Aus dem Punkt 4. ist in den letzten Jahren ein weiteres Themenfeld entstanden, welches die ersten 4 Lösungspakete wesentlich erweitert und ab heuer als eigenständige Lösung mit spezifischen Tools unter dem Namen CoMModO-PostProcessing bzw. CoMModO-PP für ausgewählte Kunden und Entwicklungspartner verfügbar ist:
- KI-basiertes Post-Processing und automatisierte Analyse von FE-Simulationsergebnissen
Ausgangssituation
Die Finite-Element-Methode (FEM) ist die maßgebliche und essentiellste Methode zur konstruktiven Entwicklung und Absicherung von Leichtbau-Maßnahmen in der Fahrzeugentwicklung, in der Luft- und Raumfahrt sowie für allgemeine, komplexe Struktur-mechanischen Aufgabenstellungen.
In der Automobil-Entwicklung ist die FEM beispielsweise durchgängig in der virtuellen Produktentwicklung integriert, industrialisiert und immanent in den Serien-Entwicklungsprozessen verankert. Dieser breite Einsatz wird durch sogenannte Simulationsdaten-Management-Systeme (SDMS) unterstützt, welche eine weitgehende Automatisierung in der Modellbildung (Pre-Processing), der Simulation (Processing) und der Auswertung der Simulationsergebnisse (Post-Processing) erlaubt. Bezüglich dem Post-Processing werden dabei nach aktuellem Stand der Technik in der Regel fest vorgegebene Auswerte-Skripte ausgeführt und die resultierenden Ergebnis-Werte in den Datenbanken und Reports des SDMS abgelegt.
Trotz steigender Komplexität der Simulationsmodelle findet eine Tiefen-Analyse einzelner Simulationen dabei immer seltener statt und benötigt die dedizierte Extraktion der Simulationen aus dem SDMS und manuelle Auswertung durch spezielle Experten. Diese brauchen in der Regel jahrelange Ausbildung und Erfahrung und sind dementsprechend immer schwieriger verfügbar. Zudem lässt die täglich Projektarbeit meist kaum Zeit für die intensive Tiefen-Analyse der Ergebnisse. Dadurch wird einerseits der fundierte Aufbau spezifischer Expertise zunehmend erschwert und es besteht die Gefahr, dass durch die weitgehende Automatisierung mit den SDMS derartiges Wissen mehr und mehr wieder verloren geht. Auch die Analyse-Qualität leidet mitunter beträchtlich, insbesondere wenn kritische Ergebnisse nicht durch die Standard-Auswertungen des SDMS erfasst werden.
Bereits vor einigen Jahren haben wir für einen unserer innovativen Premium-Kunden begonnen hierfür eine Unterstützung durch den Aufbau eines automatisierten Expertensystems zu entwickeln und ins SDMS integriert. In der ersten Anwendung wurden dabei Anomalien und Störungen in Zeitreihen-Ergebnissen automatisch erkannt und damit eine automatisierte, umfassende Plausibilisierung und Qualitätssicherung der Simulationsergebnisse im SDMS realisiert. Die Qualitätssicherung lässt sich in äquivalenter Weise auch einfach für ein Ergebnis-abhängiges, adaptives Post-Processing mit dynamischen, intelligenten Reports anstatt den statischen, fixen Ergebnis-Reports erweitern.
Innovation
Im letzten Jahr wurde dafür nun ein weiterer Meilenstein in der virtuellen Produktentwicklung durch ANDATA erzielt: in der oben beschriebenen, automatisierten, flexiblen Finite-Element-Simulationsdatenauswertung können jetzt nicht nur Zeitreihen und skalare Ergebniswerte verarbeitet werden, sondern komplette 3D-Strukturen inklusive deren Veränderung über der Zeit und Auswertung von Ergebnisgrößen wie Spannungstensoren, Verschiebungsfeldern, usw. Damit ergibt sich die Möglichkeit, dass die Ergebnisse von FE-Simulationen komplett zugänglich für die Auswertung von Mustererkennungsverfahren, Machine-Learning-basierten Klassifikations- und Prognose-Methoden oder beliebigen statistischen Auswertungen werden. So kann man damit etwa Deep-Learning-Algorithmen oder andere Neuronale Netze verwenden, um Struktur-Responses, Beulen & Knicken, Stabilitätsverlust, oder komplexere Wirkketten mit Kontakten und kombinierten Bauteilschädigungen zu erkennen und verstehen!
Technische Lösung
Technisch gesehen basiert CoMModO-PostProcessing (kurz CoMModO-PP) auf MATLAB bzw. handelt es sich um eine MATLAB-basierte API für die umfassende, automatisierte Analyse von FE-Simulationen. Im Speziellen ist die CoMModO-PP-Toolbox eine Erweiterung von ANDATAs Signal-Structure-Toolbox, welche den mathematischen Kern von Stipulator und Expectator bildet. Die Signal-Structures werden dabei neben Zeitreihen und Attributen um ein Daten-Modell für hochgradig Netz-artige, geometrische Strukturen mit zeitlich veränderlichen Eigenschaften erweitert.
Kern von CoMModO-PP ist eine umfangreiche und stetig wachsende Funktionsbibliothek, mit der auf nutzerfreundliche Weise komplexe geometrische Modelle und die darauf referenzierten Daten (wie z.B. FE-Simulationen) aufbereitet, verarbeitet und weiterführende Signaldaten und Attributen berechnet werden können.
Da CoMModO-PP auf der Signal-Structure-Toolbox aufbaut, ist sie nahtlos in den Stipulator und Expectator integriert. Somit lassen sich die Ergebnisse aus einer beliebigen Menge von Einzel-Simulationen auch für das Training von Machine-Learning-Verfahren verwalten und einfach weiterverarbeiten.
Für spezifische Auswertungen können diese von uns aber auch als Stand-Alone-Skripte oder Executables für die nahtlose und unabhängige Integration im jeweiligen Simulationsdaten-Management implementiert werden, ohne dass dafür der Stipulator oder Expectator in der Auswertung notwendig sind.
Funktionen
Die folgenden Funktionalitäten sind im derzeitigen Stand verfügbar und werden ständig erweitert und verbessert:
| Funktionsgruppe | Funktionalität |
| Selektion von Modell-Teilen und Finite-Element-Entitäten (Knoten, Elemente, Partitionen, Gruppen, Materialien, ...) |
|
| Strukturerkennungsmethoden |
|
| Berechnung von Features für das Machine-Learning |
|
| Berechnung von FE-Größen auf Basis von Modellattributen und anderen FE-Größen |
|
| Darstellung und Plotten der Modelle |
|
| Basis-Formate |
|
| Hilfs-Formate (zur Integration weiterer Solver-spezifischer (Meta-)Daten) |
|
| Integration von weiteren (Meta-)Daten |
|
| Abbildung von komplexen FE-Submodellen (Berücksichtigung von Kunden-spezifischen Modellierungskonventionen) |
|
| Expectator-Funktionalitäten |
|
| Reporting |
|
| Hilfsfunktionen |
|
Beispielhafte Anwendungen
Im Folgenden soll die Funktionalität an einem einfachen, konkreten Beispiel illustriert werden.
Das dazu verwendete FE-Simulation "NEON MODEL (NCAC V02)" stammt von National Crash Analysis Center (NCAC) der George Washington University und bildet einen Frontal-Crash eines 1996 Plymoth Neon gegen eine starre Wand ab. Das Modell ist hier von der NHTSA frei erhältlich.
Wir wollen innerhalb dieser FE-Simulation den Rand von stark deformierten Bauteile zum Zeitpunkt der größten Deformation automatisiert auf hohe Spannungen untersuchen. Erschwerend kommt hinzu, dass das im FE-Modell integrierte Gruppen-Labeling unpassend ist, weil diese z.B. zu fein/zu grob segmentiert sind.
Laden der FE-Daten
Bevor wir mit der Verarbeitung der FE-Daten beginnen können, müssen wir diese in die Signal-Structure laden. Die Einlesefunktion ssloadFEMData() erlaubt selektives Einlesen von FE-Daten. Damit ist es möglich, nur für die Verarbeitung notwendige Daten einzulesen, um Ressourcen zu schonen.
ssloadFEMData(signalstructure, {'path', 'demo_vehicle.a4db', 'loadGeometry', true, 'loadDisplacements', true, 'results', {'v. Mises (Shell/Solid)}'})
Bauteil-Erkennung
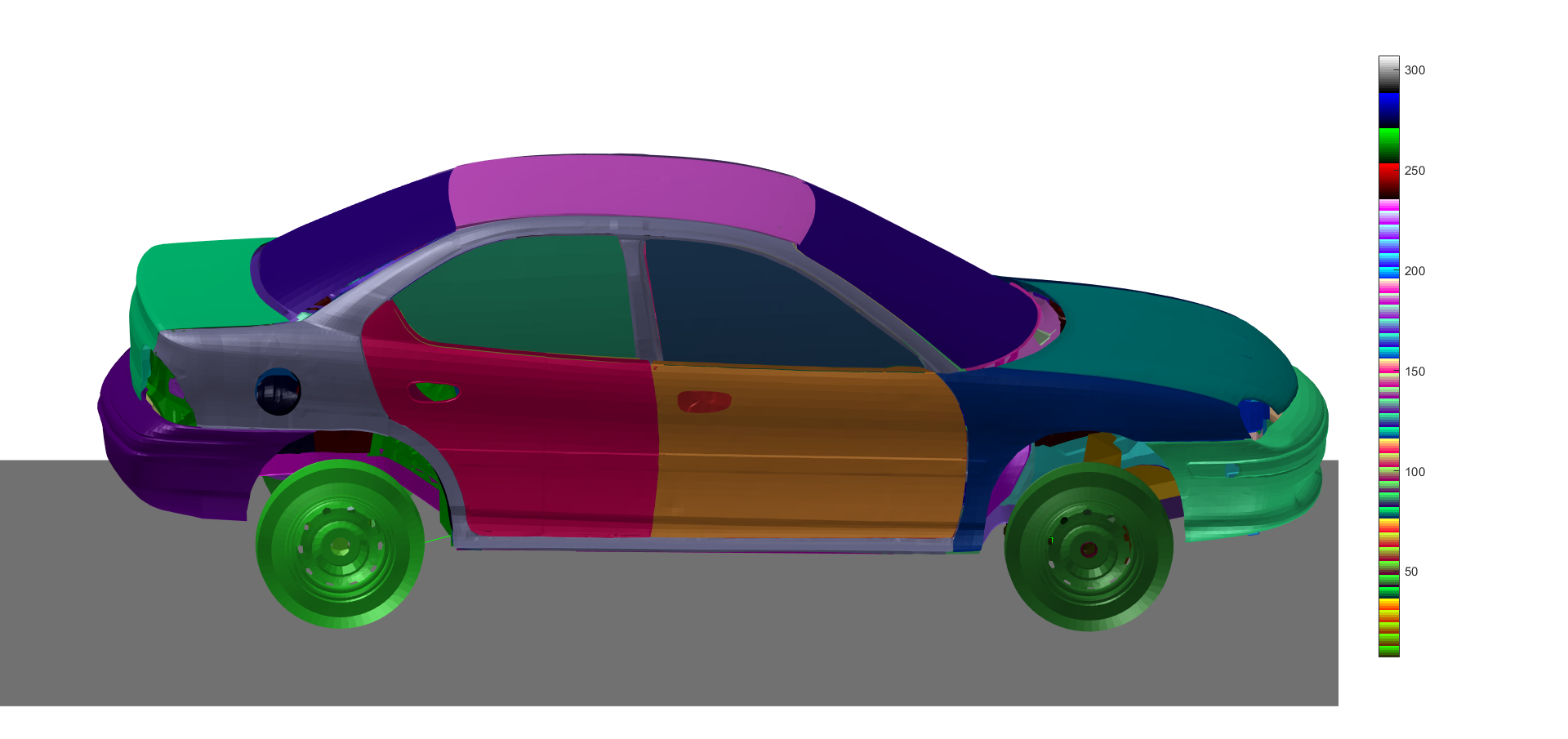
Im ersten Schritt wollen wir die zusammengehörigen Bauteile im gegebenen Modell erkennen. Hierfür wird das Modell nach zusammenhängenden Gebieten abgesucht. Mittels der Funktion ssdetectcomponents() können zusammenhängende Elemente in mehrere Gruppen unter der Entität 'myDetectedComponents' angelegt werden. Diese Gruppierungs-Entität und die zugehörigen Gruppen werden in folgenden Funktionen wieder verwendet. In dem Beispiel-Modell wurden 309 Bauteile detektiert.
ssdetectcomponents(signalstructure, {'name', 'myDetectedComponents'})
Berechnung Deformationsmaße der Bauteile
Als nächstes wollen wir ein Maß für Deformation per detektiertem Bauteil definieren, welches auf der relativen Gesamtverschiebung beruht. Zur Berechnung unseres Deformationsmaßes wollen wir aus den absoluten Verschiebungen dieser FE-Simulation Verschiebungen relativ zur Bewegung des Fahrzeugs berechnen (Eliminieren der Starrkörper-Bewegung). Um die Bewegung des Autos zu verfolgen, ist es zweckmäßig ein Bauteil zu tracken, welches in dieser Simulation kaum verformt wird.
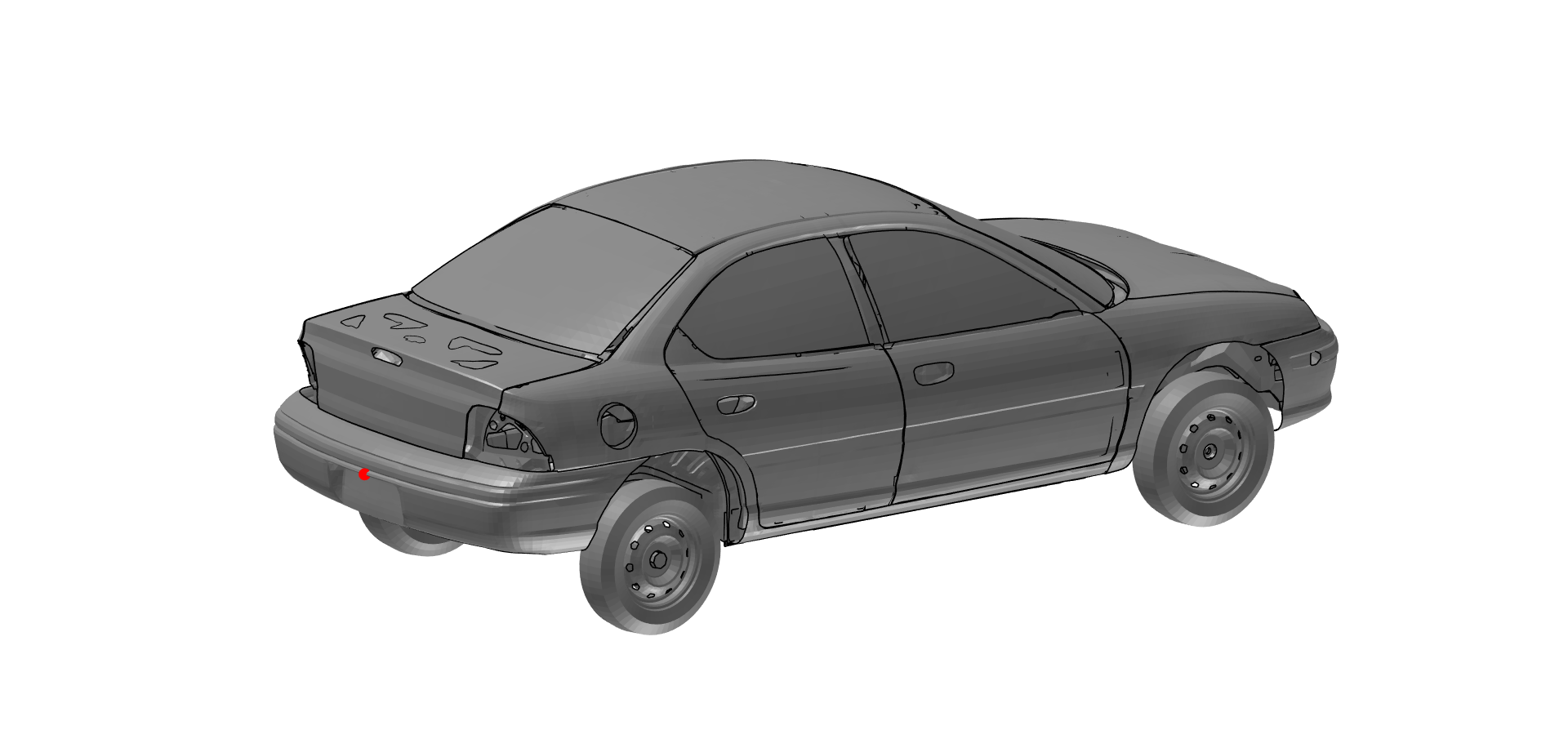
Wir nehmen daher die Heckverkleidung, weil diese am weitesten entfernt von der Barriere ist. Mit ssselectnodeattop() können wir einen Knoten identifizieren, welche am äußersten am Modell in einer definierten Richtung liegt.
ssselectnodeattop(signalstructure, {'name', 'selHeck', 'orientation', [-1,0,0]})
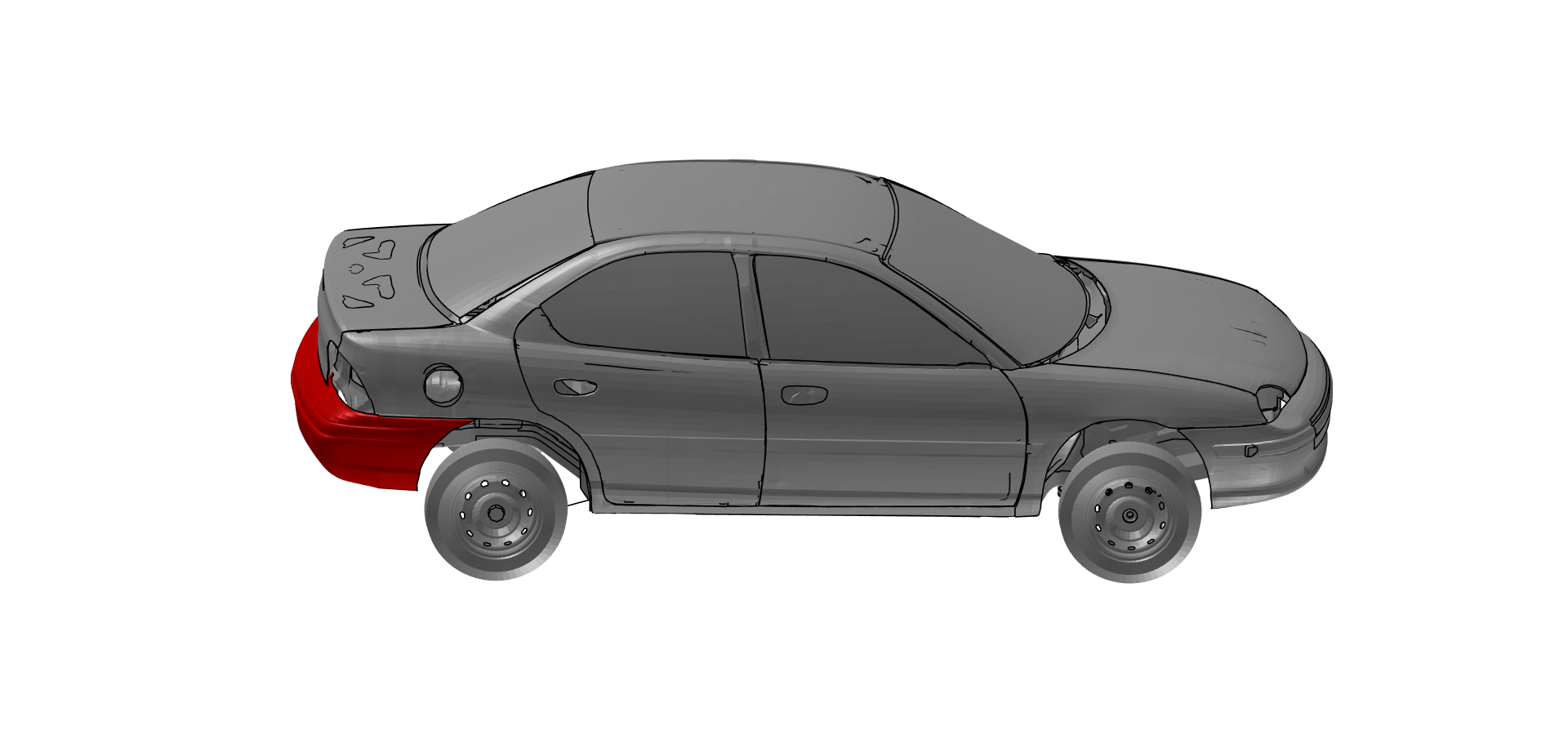
Das zugehörige Bauteil kann mittels ssconvertselection() selektiert werden. Eine Alternative wäre, ein möglichst undeformiertes Bauteil über diverse, aggregierte FE-Größen zu identifzieren.
ssconvertselection(signalstructure, {'name', 'selHeck', 'select', 'selHeck', 'entity', 'myDetectedComponents'})
Folglich wollen wir die Bewegung der Heckverkleidung über die Zeit tracken. Die zeitabhängige Lage und Orientierung einer Selektion kann mit sstrackmovement() verfolgt werden.
sstrackmovement(signalstructure, {'name', 'trackHeck', 'select', 'selHeck', 'outputMode', 'xyzrpy'})
Die absoluten Verschiebungen aus der FE-Simulation können durch sscalcrelativedisplacements() auf die ermittelte translative und rotatorische Bewegung der Heckverkleidung bezogen werden. Das Ergebnis davon sind relative Verschiebungen zur Bewegung des Automobils.
sscalcrelativedisplacements(signalstructure, {'name', {'Urel_x', 'Urel_y', 'Urel_z'}, 'select', 'selRoof', 'meth', 'xyz'}, {'trackHeck_x', 'trackHeck_y', 'trackHeck_z', 'trackHeck_roll', 'trackHeck_pitch', 'trackHeck_yaw'})
Wir wollen aus den relativen Verschiebungen ein Deformationsmaß bilden. Dazu soll durch sscalcmagnitude() die relative Gesamtverschiebung "Urel" berechnet werden. In der obigen Abbildung der relative Gesamtverschiebung sehen wir im Vergleich zur absoluten Gesamtverschiebung, dass Bereiche, die von der Bewegung des Automobils abweichen, höhere Werte aufweisen.
sscalcmagnitude(signalstructure, {'name', 'U'}, {'Ux', 'Uy', 'Uz'}) |
sscalcmagnitude(signalstructure, {'name', 'Urel'}, {'Urel_x', 'Urel_y', 'Urel_z'}) |
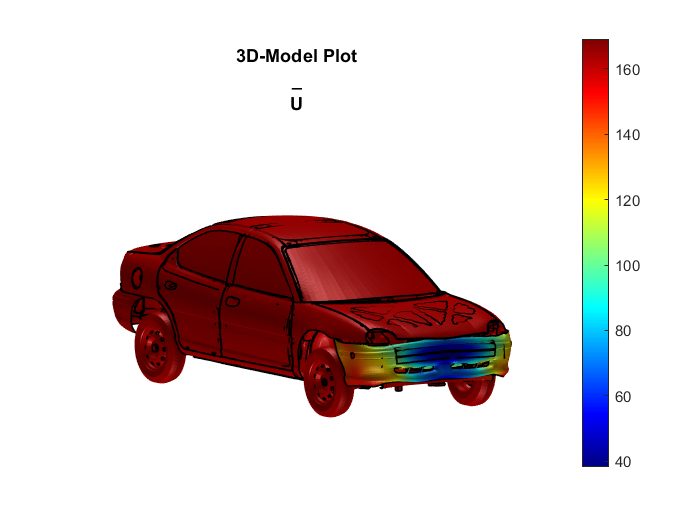 |
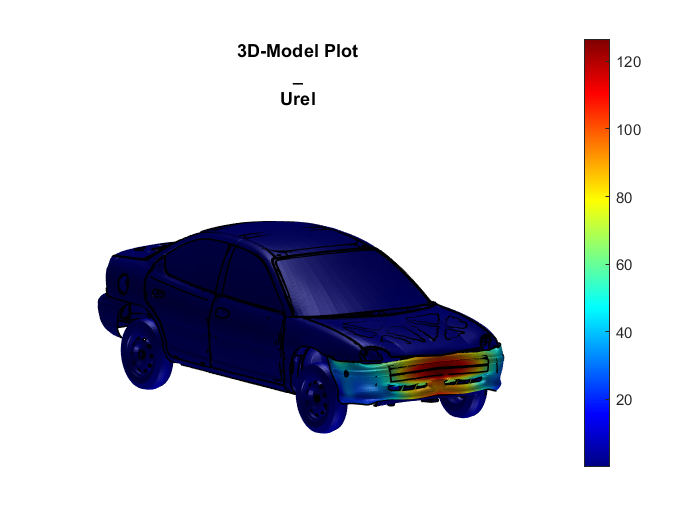 |
Wir möchten die Deformation von Bauteilen bewerten, jedoch ist die erhaltene relative Gesamtverschiebung eine Knotengröße. Mit ssaggregatebypart() kann man verschiedene Statistiken von diverse Größen statistisch für Bauteile berechnen. In unserem Fall haben wir die maximale relative Gesamtverschiebung zu dem jeweiligen Bauteil als statistische Vergleichsgröße für unser Deformationsmaß gewähl
ssaggregatebypart(signalstructure, {'name', 'Urel_max_comp', 'partKey', 'myDetectedComponents', 'meth', 'max'}, {'Urel'})

Kritische Randspannungen von stark deformierten Bauteilen
Um stark deformierte Bauteile erkennen zu können, muss zunächst festeglegt werden, ab welchen Erkennungswerten ein Bauteil als stark defomiert gilt. Zur Kalibrierung solcher Werte empfiehlt es sich, ein entsprechendes Data-Mining (z.B. mittles Stipulator, Expectator, Brainer) aufzusetzen oder mittels Expertenwissen diese Werte manuell zu justieren.
In diesem Beispiel wollen wir einfacherheitshalber einen adaptiven Schwellwert verwenden. Bauteile mit mindestens 90% der maximal auftretenden Deformation sollen als stark deformiert klassifiziert werden. Der adaptive Schwellwert kann durch sssetattr() aus der Standard-SignalProcessing des Stipulator berechnet. Bauteile, die eine größere Deformation als der definierte Schwellwert haben, werden mittels ssselectbyvalue() selektiert. Es wurden hier zwei stark deformierte Bauteile erkannt.
sssetattr(signalstructure, {'myLowerBound', '0.9 * max(max(<1>))'}, {'Urel'})
ssselectbyvalue(signalstructure, {'name', 'selHighDeformedComps', 'value', {$myLowerBound$, inf}}, {'Urel_max_comp'})

Unser Ziel ist es kritische Spannungen am Rand der stark deformierten Bauteile zu identifizieren. Den Rand der detektierten Bauteile erhalten wir durch die Funktion ssselectcontour().
ssselectcontour(signalstructure, {'name', 'selBorder', 'select', 'selHighDeformedComps'})
Eine Kontur ist beschrieben durch Knoten. Spannungen sind jedoch eine Elementgröße. Daher wollen wir die Randelemente aus der Kontur bestimmen. Hierzu können wir wieder die Konvertierungsfunktion ssconvertselection() verwenden.
ssconvertselection(signalstructure, {'name', 'selBorder', 'select', 'selBorder', 'type', 'Elements'})
Schließlich können wir die Elemente mit einer kritischen Spannung wieder mit ssselectbyvalue auswählen. Da uns nur die Elemente am Rand interessieren, können wir durch Mengenoperationen die gemeinsamen Elemente aus den relevanten Selektionen bestimmen.
ssselectbyvalue(signalstructure, {'name', 'selHighStressEls', 'value', {critStressThresh, inf}}, {'Stress'})
ssintersectselections(signalstructure, {'name', 'selHighStressBorderEls', 'select', {'selBorder', 'selHighStressEls'}})

Das Ergebnis ist eine automatisch berechnete Selektion mit Elementen, welche eine kritische Spannung am Rand von stark deformierten Bauteilen aufweist.
Die verwendete Sequenz von Funktionen der erweiterten Signal-Structure-Toolbox kann als eigenständiges Skript verwendet werden oder als Signal-Verarbeitung im Stipulator und Expectator mit allen dazugehörigen Funktionalitäten und Möglichkeiten dieser Tools.
Vorteile und Stärken
Aus den obigen Funktionalitäten ergeben sich wesentliche Vorteile der CoMModO-PP-Toolbox gegenüber festen Post-Processsing-Skripten:
- Zugänglichkeit der Inhalte in den Modellen und Resultaten: Während im traditionellen Post-Processing in der Regel nur über administrative Parameter wie die IDs, Nummern und Namen von Elementen und Gruppen erfolgt, kann jetzt über die mechanischen und strukturellen Eigenschaften der Entitäten und Bauteile auf diese zugegriffen werden. Daraus folgt ein einfacherer Zugang zu diversen FE-Problemstellungen sowie die Möglichkeit einer natürlicheren Formulierung von unterschiedlichen Kriterien.
- Flexibilität in der FE-Datenverarbeitung: Die Funktionalitäten und Kriterien können in beliebiger Weise kombiniert werden und bilden somit eine Post-Processing API, welche als dedizierte Signal-Verarbeitungen im Stipulator/Expectator zur Verfügung steht. Damit hat ein Anwender die Möglichkeit schnell und einfach Ideen zur Auswertung von FE-Daten auszuprobieren, ohne auf lange Turn-Around-Zeiten im SDMS angewiesen zu sein.
- Management von Verarbeitungen und Kriterien: Im Stipulator können FE-Datenverarbeitungen flexibel erstellt, editiert und verwaltet werden. Selbiges gilt auch für Kriterien im Expectator, wo zudem Kriterien auch adaptiert und mittels lernender Ausprägung rekalibriert werden können. Der Aufbau einer lernenden Kriterien-Datenbank ist im Prinzip ein umfassendes Expertensystem, welches Expertenwissen quantifiziert und somit für Experten aufwändige Analysen automatiiseren lassen.
- Weiterführende Daten-Analysen: Die Aufbereitung der FE-Daten für die Zugänglichkeit zu ANDATAs Data-Mining-Tools erlaubt ein maschinelles Verständnis über die strukturellen Wirkmechanismen und Zusammenhänge und somit die Identifikation von Kausalitätsketten.
- Einheitlichkeit und Multi-Disziplinarität: Der CoMModO-PP-Zugang ist Solver-unabhängig für alle Typen von FE-Simulationen möglich. Zudem wird CoMModO-PP in anderen geometrisch basierten Disziplinen erfolgreich eingesetzt. Daraus lassen sich erhebliche Synergien nutzen und die Nachhaltigkeit der Entwicklungen sicherstellen.
- MATLABs Analyse-Power: Im Anwendungsbeispiel wurden simple Schwellwert-Kriterien zur Illustration der Grundidee benutzt. Durch die Verwendung von MATLAB als Basis steht aber eine sehr viel ausgefeiltere Mathematik zur Verfügung. Etwa kann die Selektion der Bauteile über KI erfolgen, etwa indem die beschädigten Bauteile mit Deep-Learning-Verfahren nach dem Schadensbild klassifiziert werden.
Anwendungsbeispiele
Aus den beschriebenen Funktionalitäten und Vorteilen ergeben sich eine Reihe von innovativen Anwendungsfällen und neuen Möglichkeiten im Post-Processing von FE-Simulationen:
- automatisierte Plausibilisierung der Simulationsdaten und Qualitätssicherung in SDMS
- integriertes DataMining auf Struktur und Bauteileigenschaften im SDMS
- automatisiertes, intelligentes Post-Processing in SDMS
- beschleunigte Tiefen-Analyse für Experten durch neuartige Möglichkeiten der Ergebnis-Aufbereitung, etwa durch die automatisierte Identifikation und Darstellung von Ereignissen (z.B. Rebound, Kontakt, Durchdringung, Schädigung, etc.)
- Labeling von Entitäten und Strukturen nach Ereignissen und mechanischen Eigenschaften
- Grundlage zum automatisierten Wirkketten-Analyse und Aufbau eines Expertensystems aus und im SDMS
- Anwendung von virtuellen Sensoren im Nachhinein, auch wenn keine deziderten Sensoren und spezifischen Auswerte-Größen im Modell definiert wurden
Zusammenfassung
CoMModO-PP bietet ein Rahmenwerk und einen Werkzeugkasten für eine komplett neuartige Form des Postprocessing in der Finite-Element-Simulation. Damit wird die Grundlage geboten, um alle Möglichkeiten der Künstlichen Intelligenz in der FEM-Analyse einzusetzen und zur Wirkung zu bringen.
Einerseits erhalten Experten dadurch die Möglichkeit für noch tiefgreifendere Untersuchungen und die Transparenz der Wirkmechanismen in komplexen Struktur-Responses. Andererseits können Experten-Auswertungen auch besser automatisiert werden, sodass die Qualität der Analysen und Reports im Simulationsdaten-Management in neue Regionen gehoben wird.
Kontakt und weitere Informationen
Bei Interesse wenden Sie sich an info@andata.at oder die anderen bekannten ANDATA-Kontakte. Dann können wir Ihnen die Möglichkeiten von CoMModO-PP auch direkt präsentieren.
MATLAB ist eingetragene Marke von Mathworks.
Animator ist ein Produkt von GNS.
LS-Dyna ist das Finite-Element-Programm von LSTC.
Kommentare
Kommentar von Andreas |
Bitte um Beachtung, dass das Thema unter commodo in https://commodo.andata.at sowie als FEM Operations Toolbox in https://www.andata.at/de/fem-operations-toolbox.html fortgeführt wird!
Einen Kommentar schreiben