
Wieso wir die Verteilungsfunktion so lieben und das Histogramm weniger gern mögen
von Andreas Kuhn (Kommentare: 0)
Viele unserer statistischen Auswertungen machen wir in erster Linie mit der empirischen Verteilungsfunktion, obwohl ein Histogramm auf den ersten Blick intuitiver erscheint und weniger Erklärungsbedarf hat. In der Praxis hat die Verteilungsfunktion aber eine Reihe von Vorteilen, welche es Wert machen, dass man sich an diese Darstellungsform gewohnt. Die Vorteile der Verteilungsfunktion (CDF, cummulative distribution function) und die Gründe wieso wir in erster Linie diese verwenden, sollen im Folgenden nach einer grundlegenden Beschreibung an konkreten Beispielen erläutert werden.
Grundlegende Beschreibung
Bevor wir die Vorteile der einzelnen Darstellungsformen auflisten, wollen wir diese als erstes noch einmal grundsätzlich erläutern.
Gegeben sei eine Menge von Zahlen, wie sie z.B. aus beliebigen Messreihen, Simulationen oder sonstigen Datenaufzeichnungen entstehen. Zur Illustration erzeugen wir einen derartigen Satz von normalverteilten Zahlen in MATLAB per Zufallszahlengenerator:
x=randn(100,1)*10+50
Zur Darstellung dieser Zahlen in einem Histogramm wird der resultierende Zahlenbereich in eine endliche Anzahl von gleich großen Intervallen (sogenannte Bins) geteilt und gezählt wie viele der Zahlen in die jeweiligen Intervalle fallen. Die absolute oder relative Anzahl von Werten in den Intervallen wird dann als Balken aufgetragen. Das Resultat sieht dann am vorigen Beispiel etwa so aus:

Im Gegensatz dazu wird bei der Verteilungsfunktion (CDF, Cummulative Distribution Function) der relative Anteil der sortierten Werte aufgetragen. Dies entspricht eigentlich dem kontinuierlichen Integral des Histogramms.
Das Resultat sieht am vorigen Beispiel mit denselben Zahlenwerten folgendermaßen aus:

Die Darstellung bedeutet, dass jeweils eine Anteil von F(x) Werten aus der gegebenen Zahlenreihe kleiner oder gleich dem Wert x sind.
Unserer Meinung nach hat diese Darstellungsform eine Reihe von wesentlichen Vorteilen.
Direktes quantitives Ablesen wesentlicher Kenngrößen
Die Verteilungsfunktion hat gegenüber dem Histogramm u.a. den wesentlichen Vorteil, dass man wichtige Kennzahlen, wie Minimal- und Maximalwert, Median, Quantile, Percentile, etc. direkt aus der Grafik ablesen kann.

So sieht man das Minimum der Zahlenwerte direkt dort, wo der CDF beginnt und die x-Achse schneidet. Das Maximum ist direkt an der Linie y=1 abzulesen. Ebenso lassen sich die Percentile und Quantile einfach auf der x-Achse ablesen.
Jeder der Zahlenwerte ist ein konkreter Punkt auf der Verteilungsfunktion. In vielen der Plots haben wir implementiert, dass man beim Klicken auf die Linie der Verteilungsfunktion die direkten Zahlenwerte ablesen kann.
Erkennen von Ausreißern
Beim Histogramm kann es mitunter schwierig werden Ausreißer direkt am Plot zu erkennen. Fügen wir beispielsweise den Zahlenwert 400 zu der Zahlenreihe der vorigen Beispiele als Ausreißer hinzu, dann sieht das resultierende Histogramm folgendermaßen aus:

Einerseits ist bei einer großen Datenmenge der Ausreißer in der Häufigkeit kaum noch zu sehen. Andererseits vergrößert der Ausreißer die Intervalle des Histogramms derart, dass die ursprüngliche Verteilung nicht mehr erkennbar ist. Hierfür müsste man die Anzahl der Bins entsprechend des Abstands des Ausreißers deutlich erhöhen. Dies ist in der Regel aber erst im Nachhinein bekannt. Belässt man die Limits der x-Achse, ist das Vorhandensein eines Ausreißers überhaupt nicht unmittelbar bemerkbar.

Im Gegensatz dazu sieht man bei einer Verteilungsfunktion das Vorhandensein eines Ausreißers unmittelbar durch den angehängten Ausläufer, an dessen Ende sich der Wert des Ausreißers auch direkt ablesen lässt. Auch die ursprüngliche Verteilungsform bleibt weiterhin erkennbar.

Reduziert man die Limits der x-Achse, so bleibt das Vorhandensein eines Ausreißers trotzdem erkennbar, wenn die Verteilungsfunktion nicht vor dem Achsenlimit endet.

Darstellung von unendlichen Werten
Treten unendliche Werte in den Zahlen auf, so sieht man diese im Histogramm nicht. Bei der Verteilungsfunktion kann man diese insofern berücksichtigen, indem die Verteilungsfunktion nicht an der Linie y=0 beginnt bzw. an der Linie y=1 endet sondern erst bei der relativen Häufigkeit der unendlichen Werte. Dies gilt sowohl für positive als auch für negative unendliche Werte. Hin und wieder kennzeichnen wir diese mit eigenen Kreisen, um besser erkenntlich zu machen, dass die Verteilungsfunktion nicht an den Grenzlinien y=0 bzw. y=1 enden.

Erkennen des Verteilungstyps
Zugegeben - das Erkennen des Verteilungstyps ist mit dem Histogramm im ersten Blick einfacher. Am Histogramm mag man z.B. relativ schnell erkennen, dass es sich um eine Normalverteilung oder die Verteilung eines anderen Typs handelt. Andererseits kann man bei einem CDF den angenommenen Verteilungstyp mit einzeichnen und so direkt einen Kolmogorov-Smirnov-Test ausführen, indem man den maximalen y-Abstand der empirischen Verteilungsfunktion mit der angenommenen Verteilungshypothese (in der folgenden Grafik eine Standardnormalverteilung in Rot eingezeichnet) misst. Je kleiner dieser Abstand ist, umso eher entspricht die gegebene Verteilung dem angenommenen Verteilungstyp.

Erkennen von Clustern
Wie beim Typ der Verteilungsfunktion erscheint auch das Erkennen von Clustern mit dem Histogramm einfacher.

Mit etwas Übung lassen sich diese aber auch in der Verteilungsfunktion leicht erkennen. Und zwar muss man nur darauf achten, ob sich die Verteilungsfunktion verflacht und dann wieder steiler wird, wie in der folgenden Grafik für dieselben Zahlenwerte wie beim obigen Histogramm.

Vergleich von mehreren Zahlenreihen
Will man mehrere unterschiedliche Zahlenmengen miteinander vergleichen, so eignet sich die Verteilungsfunktion um einiges besser. Hierbei kann man beliebig viele Verteilungsfunktionen in einer Achse zusammenfassen und vergleichend darstellen. Dabei ist auch unerheblich wie viele Daten die einzelnen Verteilungen enthalten.

Abgesehen von den üblichen Nachteilen und abgesehen davon, dass die Ausführung des Plots komplizierter ist (z.B. müssen für alle Verteilungen einheitliche Bins ermittelt werden), wird die vergleichende Darstellung von Histogrammen sehr schnell unübersichtlich und die einzelnen Daten sind optisch nur noch schwer voneinander zu unterscheiden.

Fehl-Interpretierbarkeit und Manipulierbarkeit
Ein weiterer Nachteil des Histogramms ist der Umstand, dass die Darstellung durch ungeschickte Auswahl von Darstellungsparametern wie etwa der Bin-Size sehr unterschiedlich ausfallen kann. Nimmt man als Beispiel die folgende normalverteilte Zahlenreihe, welche vom Zufallszahlengenerator in MATLAB generiert wurde (randn(20,1)):
[0.5377, 0.5377, 1.8339, -2.2588, 0.8622, 0.3188, -1.3077, -0.4336, 0.3426, 3.5784, 2.7694, -1.3499, 3.0349, 0.7254, -0.063, 0.7147, -0.2050, -0.1241, 1.4897, 1.4090, 1.4172]
Je nachdem, wie viele Bins man für die Darstellung des Histogramms wählt, unterscheidet sich dieses deutlich:

Während die Darstellung mit 5 Bins noch den Erwartungen über die zugrundeliegende Normalverteilung entspricht, sieht die Darstellung mit 6 Bins doch deutlich anders aus und man würde eher eine multimodale Verteilung mit 3 Clustern statt der tatsächlichen Normalverteilung erwarten.
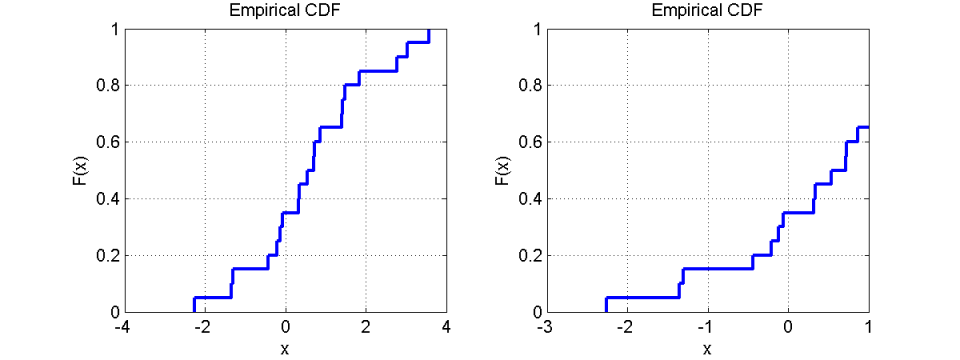
Noch dramatischer wird das Ganze, wenn auch noch die Limits der Achsen beschränkt werden:

Im Gegensatz dazu ist die Darstellung mit der kumulierten Verteilungsfunktion immer eindeutig. Bei Beschränkung der Achsenlimits bekommt man auch immer mit, wenn nicht alle Daten im Sichtbereich sind, weil die Verteilungsfunktion dann nicht bis zu den Grenzen 0 und 1 auf der y-Achse reicht. Damit ist die Verteilungsfunktion auch weniger „manipulierbar“ bzw. lassen sich Fehl-Interpretationen durch unglückliche Darstellungen besser vermeiden.
Kommentare
Einen Kommentar schreiben